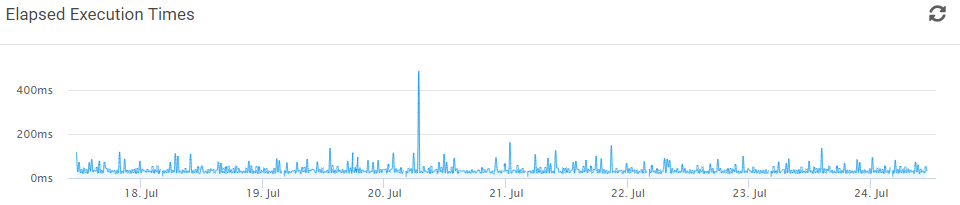
Monitoring Magento Jobs and Crons
About a month ago a client of mine was lamenting the fact that they didn’t have insight into what was going on with their cron jobs. So I did what any idiot would do
About a month ago a client of mine was lamenting the fact that they didn’t have insight into what was going on with their cron jobs. So I did what any idiot would do
Introduction A few days ago there was a question on Twitter about using Docker in production instead of development. I was a little intrigued by the question because my experience has been in the
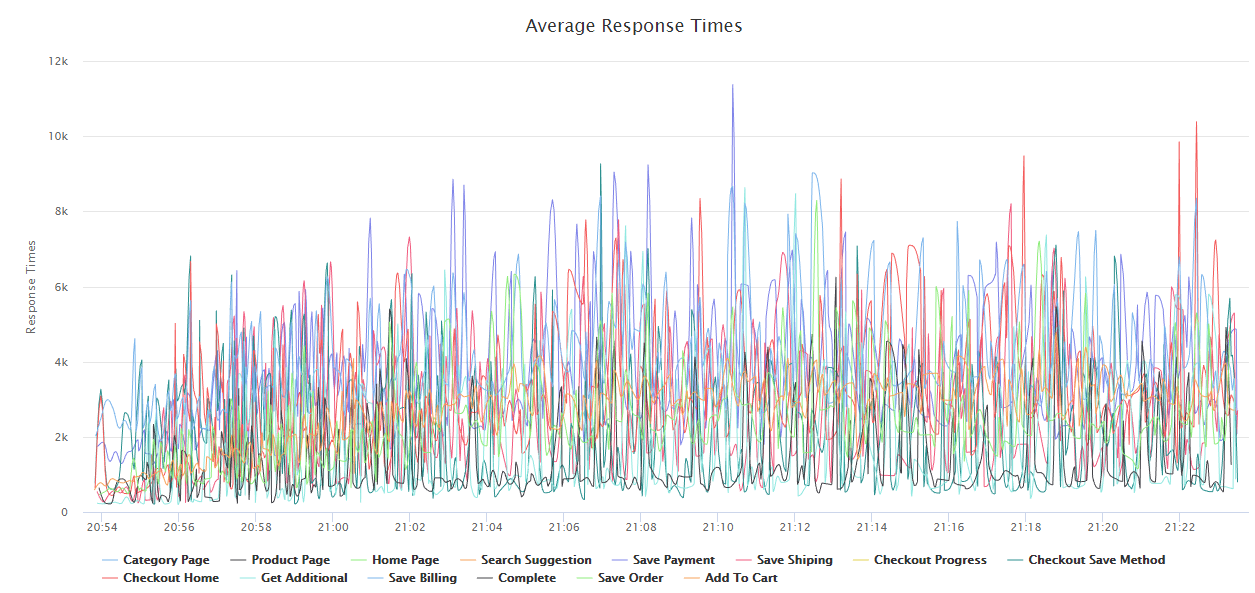
With the holiday season coming upon us more quickly than we would like, preparing your site for the holiday season is a required activity. Load testing your Magento installation is a must before your
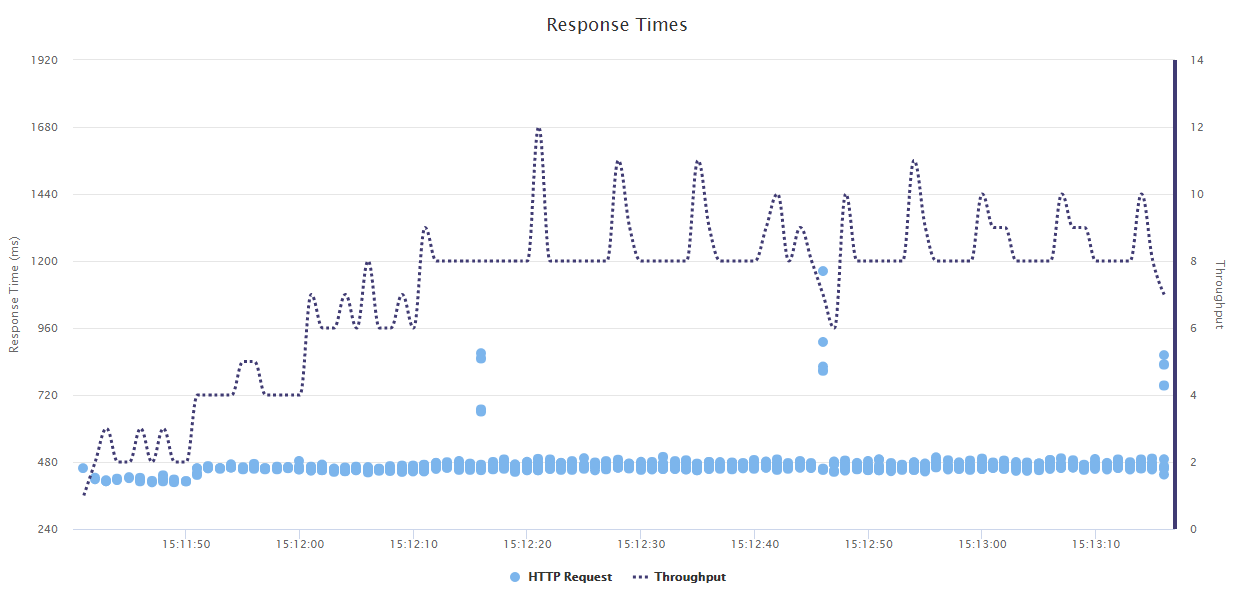
Validating SLAs (Service Level Agreements) is often part of executing browser tests. With Magium you can now include page timings as part of your test. Say, for example, that part of your SLA is
I am using the mongodb/mongodb library for a project of mine. The API seems fairly different from the old PECL library and it also came with some other, albeit unexpected, baggage. My understanding of the library
In part 1 we took a look at some of the basics of the Magento EE FPC. We talked about the general structure and flow of the FPC. In this article we are going
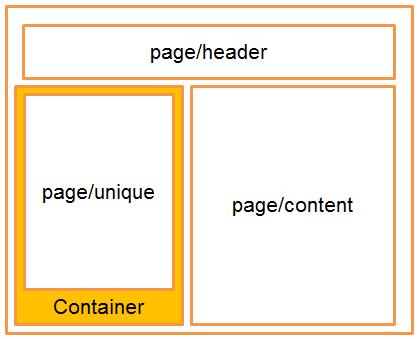
TL;DR The Full Page Cache is one of the most important performance features in Magento EE and very few people know how to use it Containers control your content Processors manage containers Knowing containers and processors gets
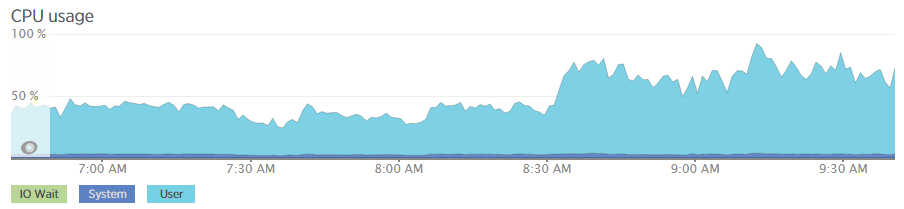
I just wrapped up a Healthcheck for a Magento ECG customer and I ran into an interesting issue. IIRC, the problem wasn’t a client one but rather code that a community extension used. I won’t
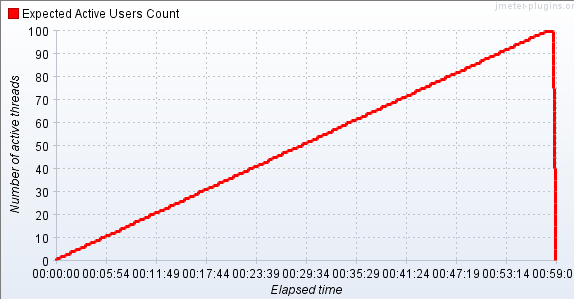
Update: I have started offering a new load testing service for Magento. Check it out! Load Testing the Magento checkout is, in theory, difficult. Well, not so much difficult as time consuming. It is
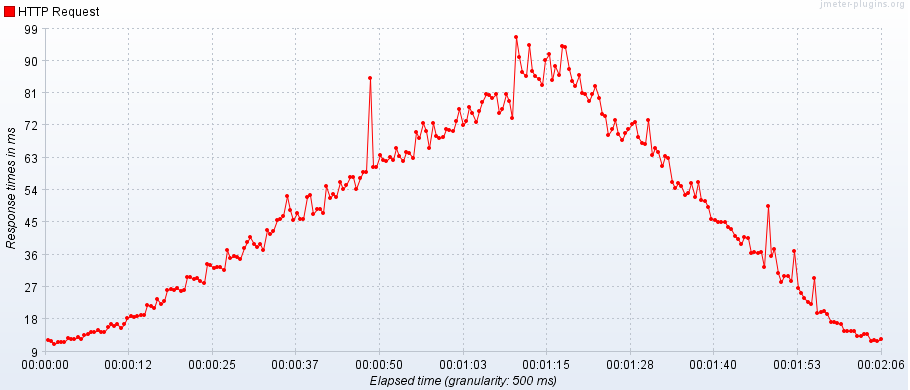
*** Personal note: It has been suggested that this may reflect an official Magento position. It does not. I like doing research and I like publishing what I find as long as I find it