So, I was having a discussion with a person I respect about logging and they noted that often logging poses a prohibitive cost from a performance perspective. This seemed a little odd to me and so I decided to run a quick series of benchmarks on my own system. Following is the code I used.
require_once 'Zend/Loader/Autoloader.php'; require_once 'Zend/Loader.php'; Zend_Loader_Autoloader::getInstance(); $levels = array( Zend_Log::EMERG => 10000, Zend_Log::ALERT => 10000, Zend_Log::CRIT => 10000, Zend_Log::ERR => 10000, Zend_Log::WARN => 10000, Zend_Log::NOTICE => 10000, Zend_Log::INFO => 10000, Zend_Log::DEBUG => 10000 ); echo '<table>'; foreach (array_keys($levels) as $priority) { @unlink('/tmp/log'); $format = '%timestamp% %priorityName% (%priority%): %message%' . PHP_EOL; $formatter = new Zend_Log_Formatter_Simple($format); $writer = new Zend_Log_Writer_Stream('/tmp/log'); $writer->addFilter(new Zend_Log_Filter_Priority($priority)); $writer->setFormatter($formatter); $logger = new Zend_Log($writer); $startTime = microtime(true); foreach ($levels as $level => $count) { for ($i = 0; $i < $count; $i++) { $logger->log( 'Warning: include(Redis.php): failed to open stream: No such file or directory in /var/www/ee1.13/release/lib/Varien/Autoload.php on line 93', $level ); } $endTime = microtime(true); echo sprintf(">tr>>td>%d>/td>>td>%f>/td>>/tr>\n", $priority, ($endTime - $startTime)); } echo '<table>'; |
What this code does is iterate over each of the different levels of logging 10k times with different levels of priority filtering for a logging message. So, basically, it will write 80,000 log entries with each iteration doing a different level of logging to see the performance overhead.

You can see the total overhead for each level of logging. This represents the total elapsed time to log 80,000 log events at the various levels of logging priority.
But nobody is logging 80,000 events (hopefully). So what does this look like for a realistic approach? Following is the breakdown based off of the elapsed time for 100 log entries for an individual request.
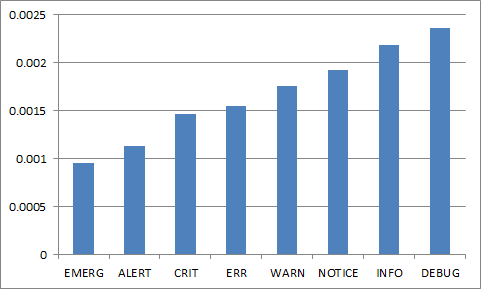
So, logging seems to cost you a sum total of 1/1000ths of a second per request (assuming 100 log entries).
So this begs the question…

Comments
shayfalador
1/1000s is pretty much. With server responding to 1000 requests per second, this becomes significant,
Also, you should remember that writing to the hard drive is slow, and doesn’t scale well, so high concurrency will probably show even worse results.
kschroeder
shayfalador There are a couple of things wrong with your assertions. First of all, hard disks being “slow” really depends on what you are comparing it to. I did a test the other day on my local drive in a VM and got about 43MB per second for writes, or 45,088,768 bytes. The logged element in my example was 140 bytes long. I would need about 300,000 writes per second for the drive interface to be saturated, simulating about 3000 requests per second. And that is on a desktop machine with an old 7200RPM hard drive. That hardly is problematic from a “scale” perspective.
A more realistic scenario that would require 100 log writes per request is that this would be a request of a moderate to complex application which would take several hundred milliseconds to run. A web server running that kind of application will not be serving 1000 requests per second, unless it is a VERY high powered machine at which point my hard drive numbers would be significantly higher because you don’t have a single 7200RPM drive on a machine like that.
What it basically comes down to is that your assertion of 1000ths of a second per request be a lot is wrong when it is put into the context of an application that would require 100 log events per second.
And when you are working with an application of this kind of complexity you will be flying blind in your production environment when you are trying to figure out why something is not behaving properly. 1/1000th of a second price for a request that takes several hundred milliseconds is peanuts when compared to the insight you can get.
shayfalador
kschroeder shayfalador First please note that I never said you shouldn’t log, I believe you should.
I still disagree with that you said. I don’t understand in these topics that much, that I feel comfortable to argue about them, but I do know that HD is slow and seek time isn’t short. So if you need to seek the log file with in every request I believe that with high concurrency you might find out some effects that you can’t see right know.
I forgot to thank you for the post in my previous comment 🙂
kschroeder
shayfalador I redid the test while watching vmstat and IOWait time was zero. System time was at 3%. I re-ran the test with 3 concurrent processes and IOWait time touched on 2 once and system time was at 8. Most of the time spent was in the logger userland code (65%).
Disks have a bad reputation as being slow, and they are… when they are functioning as memory, such as swapping. However, when disks are being used as they should be (persistent storage) I have seen very few instances where disk speed, itself, was the actual problem.
Aaron
You are right about the seek time being long. But the hard disk will not be seeking for every single write; they will likely be buffered in a write-behind cache & written to disk by DMA, while the CPU is off doing other things.
We have customers running web servers in the tens to hundreds of thousands of requests per second across the cluster. In order to do logging effectively on a site with such volume, you can make simple optimizations like disabling logging for static content if it’s a 200 response for example.
I think we can convince you 😀 I also strongly agree with Kevin; you don’t run trace-level logging in production, and the absolutely *minuscule* gain you would get from disabling request-level logging is far outweighed by the “oh shit, something went wrong and I have absolutely no idea where to start looking!”
igorS_
Hi,
and that’s why you shouldn’t write to your own logs. Use a syslog-like service.
With your own logfile every PHP request has to open the logfile, write to the file and has to close the handler. This will coast you time and it will also flush caches like stat/filesystem cache and which will BTW flush the disk cache and and the so important realpath cache.
If you log into syslog for example, you don’t have to care. This is cheap. And if your syslog service (I recommend rsyslog) is properly configured, you won’t notice.
gsg
Well, depends on what system you are writing but in real time systems dealing with tens of thousands of requests per second where latency matters – this matters.
In addition – log are not usually hard coded with fixed message – they should be as descriptive as possible.
therefore in most cases you would construct a sting with changing variables (unlike the fixed string in your example). This construction is evaluated whether log level is info, debug, error or whatever and takes more computation time.
In addition – more complicated systems that are not you example push systems to their limits (Memory wise, Thread wise) and i can assure you that this addition of memory usage and context switching will not be appreciated.
Logs are very important and should be as descriptive as possible – but should now be taken as not affecting at all.